
How We Built 15Five’s Data Platform

15Five is the strategic performance management platform that drives action and impact. It helps HR teams take strategic action and transforms leaders into changemakers. 15Five’s complete, AI-powered platform includes 360° performance reviews, engagement surveys, action planning, goal tracking, manager enablement, and manager-employee feedback tools.
We need robust data systems that can process, analyze, and surface insights from millions of employee interactions to deliver these capabilities at scale. Our engineering team built a sophisticated data platform that powers these features and enables strategic decision-making for HR leaders. Here’s how we did it.
15Five’s Data Platform Goals
The primary goal in building our data platform was to improve 15Five’s reporting and analytics capabilities, empowering HR admins with actionable insights into employee performance and engagement. The platform uses historical data to enable trend analysis, giving HR professionals a clearer understanding of workforce dynamics over time.
Beyond daily reporting, the platform allows us to perform advanced business intelligence and predictive analytics using machine learning and deep learning models. These models help HR teams predict employee turnover and identify the key drivers of engagement, allowing organizations to take proactive actions to enhance their work environment.
Before implementing this data platform, our data was scattered across multiple systems, making it difficult to consolidate and analyze. The new platform provides a unified solution that powers our Outcomes Flywheel and supports future application development.
The Data
Most of our data originates from 15Five’s application databases, primarily powered by Amazon RDS Postgres and RDS Aurora (Postgres engine). At the core sits a large Postgres instance supporting our monolithic application and a shared database used by several other microservices.
These databases store key operational data essential for driving insights across the platform. Our centralized data processing enables cohesive reporting and analysis using data from all areas of the application ecosystem.
The Technology Stack
Since 15Five operates largely in the AWS ecosystem, it was natural to use AWS technologies when building the data platform. This approach ensures scalability, security, and consistency across our infrastructure.
For our data warehouse solution, we chose AWS Redshift Serverless because it:
- Automatically scales compute resources based on demand
- Eliminates manual infrastructure management
- Efficiently handles fluctuating workloads
- Ensures continuous data availability for analytics
- Prevents resource over-provisioning
Data Platform Architecture – High-Level Overview
We chose a Data Lake architecture to provide both flexibility and scalability. Amazon S3 serves as our single source of truth, ensuring data is centralized and readily available for analytics, reporting, and machine learning workloads that support strategic HR decisions.
The Data Lake architecture also gives us complete control over the data ingestion cadence for agile decision-making. This means we can optimize when and how data is processed, reducing costs, particularly with our serverless Redshift data warehouse. We align data ingestion with business requirements to maintain efficiency without overprovisioning.
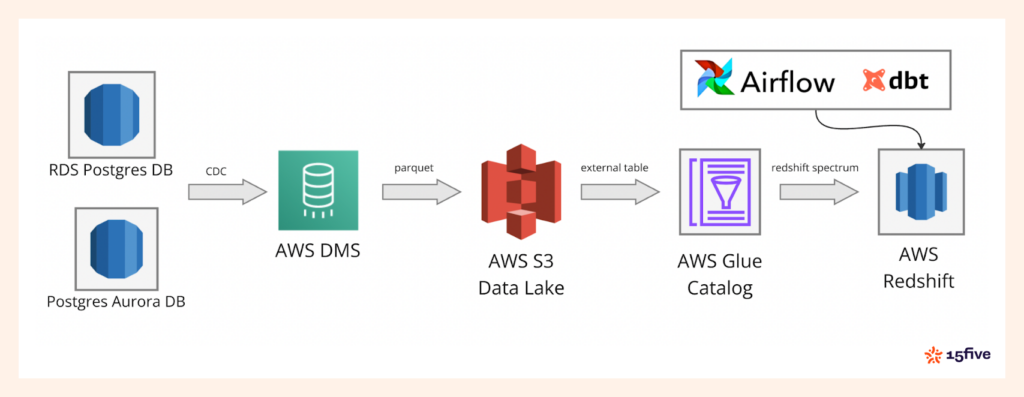
In the diagram above, you can see the full architecture, starting with data ingestion via AWS DMS into the S3-based Data Lake. From there, AWS Glue Catalog manages metadata, while Redshift Spectrum processes the data. The entire workflow is orchestrated using Apache Airflow and dbt, ensuring smooth data operations and transformations.
Data Ingestion
Our data pipeline ingests data from over 100 transactional database tables. We wanted an easy-to-maintain, scalable solution for this process, and AWS Data Migration Service (DMS) fit the bill. DMS facilitates seamless data replication from our transactional databases into the Data Lake.
We partition the data with hourly granularity, which makes it easier to query and manage specific time periods. The Parquet file format helps us optimize storage and retrieval, ensuring efficient queries for analytics downstream.
This architecture allows us to handle large data volumes while maintaining flexibility as we scale.
Data Catalog with AWS Glue
To allow Redshift to query data stored in S3, we use AWS Glue to create external schemas that map to S3 prefixes representing our various data tables. Once the Glue database and tables are set up, we have two options:
- Use Glue Crawlers to automatically infer the schema and partitions.
- Use an AWS DMS feature that automatically updates the Glue Catalog as new data arrives.
However, we encountered reliability issues with the DMS feature—it caused frequent crashes, leading to replication slots in the source databases being dropped. This caused data loss, which contradicted the ease-of-maintenance goal we initially sought.
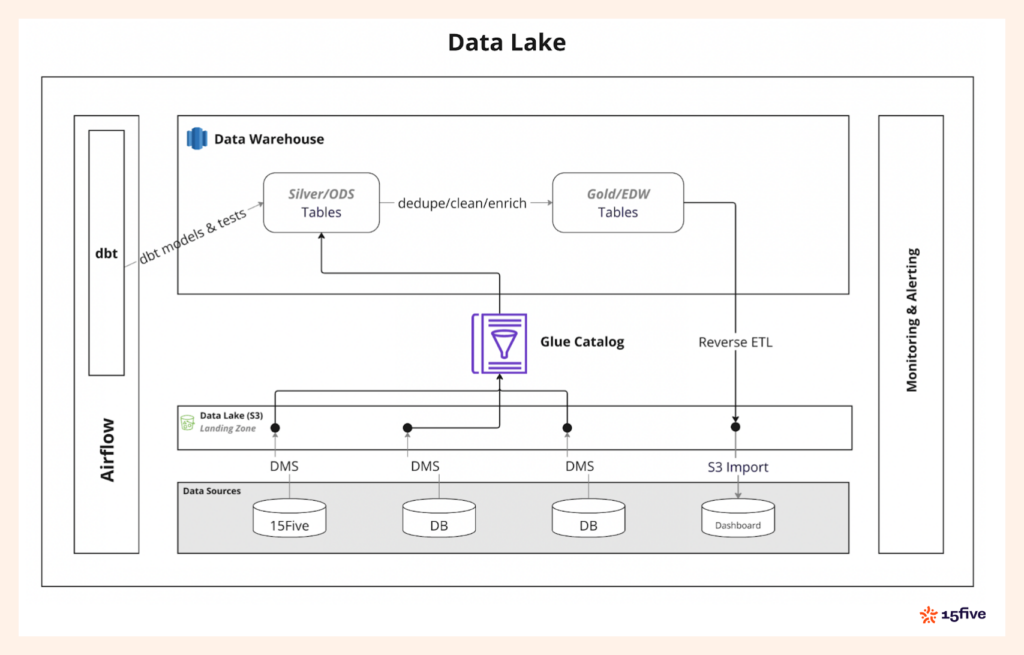
As a solution, we developed a custom process using AWS SNS and AWS Lambda to automatically update the Glue Catalog and partitions when new files land in S3. This in-house solution has ensured real-time Glue metadata and partition updates, providing a more reliable alternative to DMS features.
Data Transformation with dbt
For data transformation, we rely on dbt (data build tool). Using dbt, we transform raw data into progressively cleaner, deduped, more refined layers, following the medallion architecture. This approach ensures that each layer of data is better structured and more suitable for downstream analytics.
The modular approach of dbt maintains consistent, reliable data transformations. Our staged transformation process ensures data is always structured and optimized for reporting.
Data Quality & Testing
To maintain the integrity of our data, we implement thorough testing using dbt and Great Expectations. For dbt, we define tests in model properties YAML files, validating key data quality metrics like uniqueness, non-null values, and relationships between tables. These tests run during the transformation process, catching any issues early on.
We also perform unit tests on dbt models before deployment, ensuring no structural or logical issues impact the accuracy of the model output and the downstream data. For data consumed by external systems (such as in reverse ETL), we follow a Write, Audit, Publish pattern to validate the data.
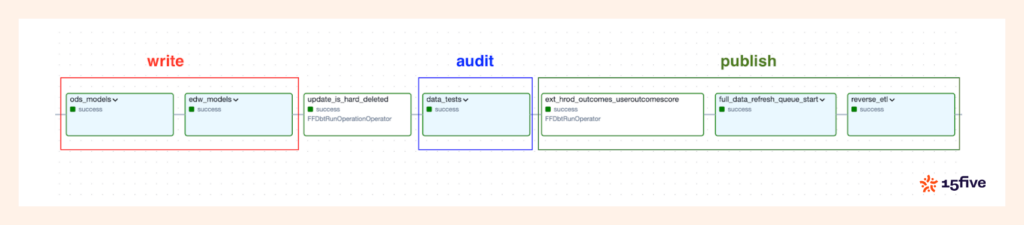
If any test fails, the entire pipeline (DAG) is halted, and our team is notified via OpsGenie. This prevents bad data from being ingested into the application databases or reaching customers.
Reverse ETL for Processed Data
To serve the transformed data back to the customer-facing application, we reverse ETL the data into our application databases. We unload data from Redshift into an S3 bucket using Redshift’s UNLOAD query. From there, we use PostgreSQL’s s3_import feature to import the data back into the Postgres database that powers the application UI.
This reverse ETL process ensures that the transformed data is efficiently returned to the application, using upserts with Postgres’ INSERT with ON CONFLICT to maintain data consistency without duplication.
Additional Tooling
Our entire infrastructure is provisioned using Infrastructure-as-Code (IaC) through Terraform. This allows us to automate the deployment and management of our environments, making the process repeatable and reducing manual effort.
We use Apache Airflow to orchestrate the entire data pipeline, from data transformation with dbt to reverse ETL. Airflow enables us to manage complex workflows efficiently, ensuring each step of the process is executed correctly with visibility into any potential issues.
Conclusion
Building a robust data platform requires careful consideration of architecture, tools, and workflows. We’ve created a scalable, flexible, and efficient platform that benefits both internal teams and external customers using technologies like AWS DMS, AWS Redshift, dbt, Apache Airflow, and others.
This platform allows us to handle large volumes of data, ensure its quality, and deliver timely insights that drive business decisions.
We’re Hiring
At 15Five, we’re always looking for talented engineers and data scientists. If you’re interested in helping us build the next generation of HR technology data management, apply for our open roles here.
About the author: Ujwal Trivedi is a Principal Engineer at 15Five and leads the development of the company’s Data Platform, enabling AI-driven Strategic-HR and Performance Management products. He focuses on building scalable, data-driven infrastructure that powers 15Five’s AI and analytics for HR leaders.